

ConoHa WING上にPythonのスクリプトを配置してスクレイピングをするための手順メモ。
ConoHa WINGでPythonを使うための設定などはこちらの記事を参照。

Chromium&ChromeDriverを取得
SSHで接続して、以下のシェルを実行します。
local=${HOME}/local
work_local=${HOME}/work_local
# ver.112.0.5615.49
revision=1109227
# Download & Install Chromium
chromium_url="https://www.googleapis.com/download/storage/v1/b/chromium-browser-snapshots/o/Linux_x64%2F${revision}%2Fchrome-linux.zip?alt=media"
chromium_file="${work_local}/chromium${revision}.zip"
curl -# ${chromium_url} > ${chromium_file}
unzip -d ${local} ${chromium_file}
mv ${local}/chrome-linux ${local}/chromium${revision}
export PATH=${local}/chromium${revision}:${PATH}
sed -i -e '$a export PATH='${local}'/chromium'${revision}':${PATH}' ${HOME}/.bash_profile
# Download ChromeDriver
driver_url="https://www.googleapis.com/download/storage/v1/b/chromium-browser-snapshots/o/Linux_x64%2F${revision}%2Fchromedriver_linux64.zip?alt=media"
driver_file="${work_local}/chromedriver${revision}.zip"
curl -# ${driver_url} > ${driver_file}
unzip -j -d ${work_local} ${driver_file}
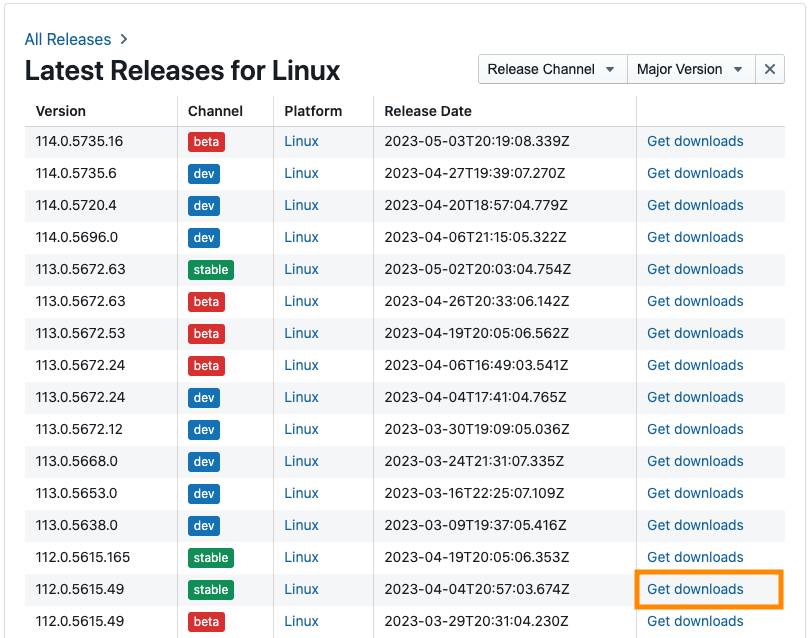
cp -f ${work_local}/chromedriver ${local}/chromium${revision}/chromedriverrevisionの確認方法
revisionはここで確認。
上記ではver.112.0.5615.49を導入していますが、Channelが”stable”になっている最新バージョンを入れれば良いと思います。

SeleniumとBeautifulSoupをインストール
Seleniumをインストールします。
$ pip install seleniumBeautifulSoupをインストールします。(任意)
$ pip install beautifulsoup4スクレイピングの実装
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from bs4 import BeautifulSoup
from time import sleep
# ブラウザウィンドウを表示しないためのオプションを設定
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
# 証明書エラーを回避するための設定
capabilities = DesiredCapabilities.CHROME.copy()
capabilities["acceptInsecureCerts"] = True
# ドライバを設定して、サービスインスタンスを作成
service = webdriver.chrome.service.Service(
# 上記でダウンロードしたChromeDriverのパス
# => ${local}/chromium${revision}/chromedriver
executable_path="<chromedriverのパス>"
)
# スクレイピング実行
with webdriver.Chrome(
service=service, options=options, desired_capabilities=capabilities
) as driver:
# HTMLデータ取得
# ※非同期でページ読み込みされるのを待機するためにsleepを使用しているが、
# WebDriverWaitを使用するほうが良いと思う(手抜き)
driver.get("<url>")
sleep(2)
content = driver.page_source
# データ解析はBeautifulSoupで行う(そのままSeleniumで解析しても良い)
soup = BeautifulSoup(content, 'html.parser')
# あとは煮るなり焼くなり茹でるなり・・・
